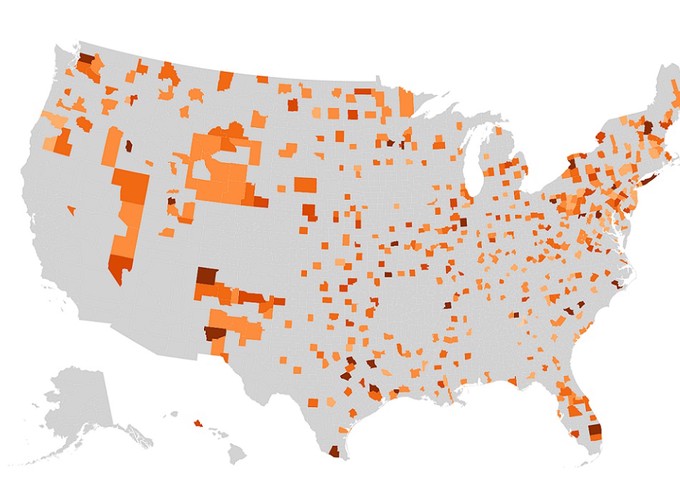
Please visit https://mhberro.github.io/ to interact with the Climate Migration tool. Drag the “Select Year” slider to change the prediction year and click on the shaded regions to display the climate index for that region.
Problem Statement
Migration due to climate change is already occurring in the U.S and around the world. This can be impacted by many factors, such as recurrent flooding, rising temperature and humidity, and repeated fire outbreaks. As the pattern of climate change continues, many cities will become uninhabitable. The goal of this project is to create an interactive visualization of the effects of climate change on the U.S. over the next 50 years and recommend better areas to move to based on predicted climate values.
Data
I was able to retrieve the climate data by scraping it from the National Oceanic and Atmospheric Administration (NOAA) API. The NOAA database has daily climate information dating back to the 1950s for differenct zip codes. I initially planned to scrape all 42,000 zip codes in the U.S for climate data, but the NOAA API has a stict limit on requests per day, and it would take roughly 25,500 days to scrape for each zip code. Instead, I used a subset of 1000 zip codes, using the first three digits, which represent the zip code prefix, to get all the regions in the U.S. Climate data is regional, but doesn’t change drastically within small regions. This allows me to get an approximation of the climate data for all the zips by using a smaller (but still quite large), more manageable subset. The total amount of data is over 70 million records that is stored in MySQL on an EC2 instance in AWS.
Below is the model used to make wildfire predictions for the Climate Migration tool. This model is one of a number of models used to create the overall climate index prediction for the Climate Migration app. The data was obtained from scraping the National Oceanic and Atmospheric Administration (NOAA) website.
import pandas as pd
import zipfile
import numpy as np
import random
from sklearn.model_selection import train_test_split
from sklearn.neural_network import MLPClassifier
from sklearn.metrics import confusion_matrix, roc_auc_score
from sklearn import preprocessing, metrics
from sklearn.ensemble import RandomForestClassifier
import matplotlib.pyplot as plt
Content
1. Clean data
-
- Clean weather data
-
- Clean disaster data and extract fire data
-
- Join weather and fire data
2. Train model
-
- Train test split
-
- Scale and downsample
-
- MLP classifier
-
- Random forest classifier
3. Prediction future fire
-
- Load predicted weather data
-
- Scale predicted weather data
-
- Predict fire
Clean data
1) Clean weather data
zp = zipfile.ZipFile('cleaned_data/all_zip_codes_all.zip')
weather_df = pd.read_csv(zp.open("all_zip_codes.csv"), converters={'zip': lambda x: str(x)}) #include leading zeros
weather_df.head()
#zip is same as zipcode, except that zip includes leading zeros
|
date |
zipcode |
zip |
PRCP |
SNOW |
SNWD |
TMAX |
TMIN |
TOBS |
| 0 |
1950-01-01 |
601 |
00601 |
18.0 |
0.0 |
0.0 |
183.0 |
128.0 |
156.0 |
| 1 |
1950-01-02 |
601 |
00601 |
18.0 |
0.0 |
0.0 |
194.0 |
122.0 |
167.0 |
| 2 |
1950-01-03 |
601 |
00601 |
0.0 |
0.0 |
0.0 |
211.0 |
133.0 |
183.0 |
| 3 |
1950-01-04 |
601 |
00601 |
0.0 |
0.0 |
0.0 |
200.0 |
144.0 |
167.0 |
| 4 |
1950-01-05 |
601 |
00601 |
0.0 |
0.0 |
0.0 |
217.0 |
139.0 |
167.0 |
|
date |
zipcode |
zip |
PRCP |
SNOW |
SNWD |
TMAX |
TMIN |
TOBS |
| 10955519 |
2020-10-22 |
39701 |
39701 |
0.0 |
0.0 |
0.0 |
272.0 |
183.0 |
233.0 |
| 10955520 |
2020-10-23 |
39701 |
39701 |
0.0 |
0.0 |
0.0 |
289.0 |
206.0 |
222.0 |
| 10955521 |
2020-10-26 |
39701 |
39701 |
0.0 |
0.0 |
0.0 |
206.0 |
133.0 |
172.0 |
| 10955522 |
2020-10-27 |
39701 |
39701 |
0.0 |
0.0 |
0.0 |
256.0 |
156.0 |
161.0 |
| 10955523 |
2020-10-28 |
39701 |
39701 |
0.0 |
0.0 |
0.0 |
250.0 |
161.0 |
228.0 |
Index(['date', 'zipcode', 'zip', 'PRCP', 'SNOW', 'SNWD', 'TMAX', 'TMIN',
'TOBS'],
dtype='object')
10955524
weather_df['zipcode'].nunique()
652
weather_df['zipcode'].unique()[:100]
array([ 601, 703, 901, 1201, 1301, 1420, 1501, 1602, 1701,
1801, 2019, 2108, 2301, 2420, 2601, 3031, 3101, 3301,
3431, 3561, 3740, 3801, 3901, 4001, 4101, 4210, 4330,
4401, 4530, 4605, 4730, 4841, 4901, 5001, 5101, 5201,
5301, 5401, 5602, 5701, 5819, 6001, 6103, 6226, 6320,
6401, 6604, 6801, 7001, 7102, 7302, 7501, 7701, 7901,
8201, 8302, 8401, 8701, 8801, 8901, 10801, 10901, 11001,
11101, 11501, 11701, 89001, 89101, 89301, 89701, 89801, 90401,
90501, 90601, 90701, 90802, 91001, 91101, 91201, 91301, 91401,
91501, 91601, 91701, 91901, 92101, 92201, 92301, 92501, 92602,
92701, 93001, 93101, 93401, 93501, 93601, 93901, 94002, 94102,
94301])
weather_df['zip'].nunique()
652
weather_df['zip'].unique()[:100]
array(['00601', '00703', '00901', '01201', '01301', '01420', '01501',
'01602', '01701', '01801', '02019', '02108', '02301', '02420',
'02601', '03031', '03101', '03301', '03431', '03561', '03740',
'03801', '03901', '04001', '04101', '04210', '04330', '04401',
'04530', '04605', '04730', '04841', '04901', '05001', '05101',
'05201', '05301', '05401', '05602', '05701', '05819', '06001',
'06103', '06226', '06320', '06401', '06604', '06801', '07001',
'07102', '07302', '07501', '07701', '07901', '08201', '08302',
'08401', '08701', '08801', '08901', '10801', '10901', '11001',
'11101', '11501', '11701', '89001', '89101', '89301', '89701',
'89801', '90401', '90501', '90601', '90701', '90802', '91001',
'91101', '91201', '91301', '91401', '91501', '91601', '91701',
'91901', '92101', '92201', '92301', '92501', '92602', '92701',
'93001', '93101', '93401', '93501', '93601', '93901', '94002',
'94102', '94301'], dtype=object)
date object
zipcode int64
zip object
PRCP float64
SNOW float64
SNWD float64
TMAX float64
TMIN float64
TOBS float64
dtype: object
# map zip code to fips code for weather data
zip_fips_df = pd.read_csv("cleaned_data/ZIP-COUNTY-FIPS_2017-06.csv")
zip_fips_df['ZIP'].unique()
array([36003, 36006, 36067, ..., 820, 830, 802])
weather_fips_df = weather_df.merge(zip_fips_df, how = 'left', left_on = 'zipcode', right_on='ZIP')
#get weather data with fips code
weather_fips_df.head()
|
date |
zipcode |
zip |
PRCP |
SNOW |
SNWD |
TMAX |
TMIN |
TOBS |
ZIP |
COUNTYNAME |
STATE |
FIPS code |
| 0 |
1950-01-01 |
601 |
00601 |
18.0 |
0.0 |
0.0 |
183.0 |
128.0 |
156.0 |
601 |
Adjuntas Municipio |
PR |
72001 |
| 1 |
1950-01-01 |
601 |
00601 |
18.0 |
0.0 |
0.0 |
183.0 |
128.0 |
156.0 |
601 |
Ponce Municipio |
PR |
72113 |
| 2 |
1950-01-02 |
601 |
00601 |
18.0 |
0.0 |
0.0 |
194.0 |
122.0 |
167.0 |
601 |
Adjuntas Municipio |
PR |
72001 |
| 3 |
1950-01-02 |
601 |
00601 |
18.0 |
0.0 |
0.0 |
194.0 |
122.0 |
167.0 |
601 |
Ponce Municipio |
PR |
72113 |
| 4 |
1950-01-03 |
601 |
00601 |
0.0 |
0.0 |
0.0 |
211.0 |
133.0 |
183.0 |
601 |
Adjuntas Municipio |
PR |
72001 |
16380869
2) Clean disaster data and extract fire data
# data description: https://www.fema.gov/openfema-data-page/disaster-declarations-summaries-v2
disaster_df = pd.read_csv("cleaned_data/DisasterDeclarationsSummaries_1.1.csv")
Index(['femaDeclarationString', 'disasterNumber', 'state', 'declarationType',
'declarationDate', 'fyDeclared', 'incidentType', 'declarationTitle',
'ihProgramDeclared', 'iaProgramDeclared', 'paProgramDeclared',
'hmProgramDeclared', 'incidentBeginDate', 'incidentEndDate',
'disasterCloseoutDate', 'fipsStateCode', 'helperState',
'fipsCountyCode', 'helperCounty', 'fipscode', 'placeCode',
'designatedArea', 'declarationRequestNumber', 'hash', 'lastRefresh',
'id'],
dtype='object')
|
femaDeclarationString |
disasterNumber |
state |
declarationType |
declarationDate |
fyDeclared |
incidentType |
declarationTitle |
ihProgramDeclared |
iaProgramDeclared |
... |
helperState |
fipsCountyCode |
helperCounty |
fipscode |
placeCode |
designatedArea |
declarationRequestNumber |
hash |
lastRefresh |
id |
| 0 |
DR-1-GA |
1 |
GA |
DR |
1953-05-02T04:00:00.000Z |
1953 |
Tornado |
TORNADO |
0 |
1 |
... |
13 |
0 |
0 |
13000 |
0 |
Statewide |
53013 |
2f28952448e0a666d367ca3f854c81ec |
2020-10-05T14:21:20.694Z |
5f7b2be031a8c6681cfb4342 |
| 1 |
DR-2-TX |
2 |
TX |
DR |
1953-05-15T04:00:00.000Z |
1953 |
Tornado |
TORNADO & HEAVY RAINFALL |
0 |
1 |
... |
48 |
0 |
0 |
48000 |
0 |
Statewide |
53003 |
c5a1a4a1030d6730d9c562cdbe7c830f |
2020-10-05T14:21:20.696Z |
5f7b2be031a8c6681cfb4345 |
| 2 |
DR-5-MT |
5 |
MT |
DR |
1953-06-06T04:00:00.000Z |
1953 |
Flood |
FLOODS |
0 |
1 |
... |
30 |
0 |
0 |
30000 |
0 |
Statewide |
53006 |
59c5483387ca13c6a3c1bc692f4860e1 |
2020-10-05T14:21:20.698Z |
5f7b2be031a8c6681cfb4348 |
| 3 |
DR-7-MA |
7 |
MA |
DR |
1953-06-11T04:00:00.000Z |
1953 |
Tornado |
TORNADO |
0 |
1 |
... |
25 |
0 |
0 |
25000 |
0 |
Statewide |
53009 |
6bab17e16984fc75f61a8445df3e95d9 |
2020-10-05T14:21:20.699Z |
5f7b2be031a8c6681cfb434b |
| 4 |
DR-8-IA |
8 |
IA |
DR |
1953-06-11T04:00:00.000Z |
1953 |
Flood |
FLOOD |
0 |
1 |
... |
19 |
0 |
0 |
19000 |
0 |
Statewide |
53008 |
e258e9dd25fac73939f59c8ffb5308f5 |
2020-10-05T14:21:20.700Z |
5f7b2be031a8c6681cfb434e |
5 rows × 26 columns
disaster_df['declarationDate']
0 1953-05-02T04:00:00.000Z
1 1953-05-15T04:00:00.000Z
2 1953-06-06T04:00:00.000Z
3 1953-06-11T04:00:00.000Z
4 1953-06-11T04:00:00.000Z
...
60218 2020-10-08T17:30:00.000Z
60219 2020-10-08T17:30:00.000Z
60220 2020-10-08T17:30:00.000Z
60221 2020-10-08T17:30:00.000Z
60222 2020-09-20T16:40:00.000Z
Name: declarationDate, Length: 60223, dtype: object
disaster_df['incidentType'].nunique(), disaster_df['declarationTitle'].nunique()
(23, 2128)
disaster_df['incidentType'].unique()
array(['Tornado', 'Flood', 'Fire', 'Other', 'Earthquake', 'Hurricane',
'Volcano', 'Severe Storm(s)', 'Toxic Substances', 'Typhoon',
'Dam/Levee Break', 'Drought', 'Snow', 'Severe Ice Storm',
'Freezing', 'Coastal Storm', 'Fishing Losses', 'Mud/Landslide',
'Human Cause', 'Terrorist', 'Tsunami', 'Chemical', 'Biological'],
dtype=object)
disaster_df[disaster_df['incidentType'] == "Fire"]['declarationTitle'].unique()
#use "incidentType"
array(['FOREST FIRE', 'FIRES', 'FIRE (LOS ANGELES COUNTY)', ...,
'ZOGG FIRE', 'SQF FIRE COMPLEX', 'SOUTH OBENCHAIN FIRE'],
dtype=object)
disaster_df['fire'] = disaster_df['incidentType'].apply(lambda x:1 if x == 'Fire' else 0)
len(disaster_df[~(disaster_df['declarationDate'] == disaster_df['incidentBeginDate'])])
disaster_df[~(disaster_df['declarationDate'] == disaster_df['incidentBeginDate'])].head()
|
femaDeclarationString |
disasterNumber |
state |
declarationType |
declarationDate |
fyDeclared |
incidentType |
declarationTitle |
ihProgramDeclared |
iaProgramDeclared |
... |
fipsCountyCode |
helperCounty |
fipscode |
placeCode |
designatedArea |
declarationRequestNumber |
hash |
lastRefresh |
id |
fire |
| 4974 |
DR-546-MA |
546 |
MA |
DR |
1978-02-10T05:00:00.000Z |
1978 |
Flood |
COASTAL STORMS, FLOOD, ICE & SNOW |
0 |
1 |
... |
1 |
1 |
25001 |
99001 |
Barnstable (County) |
78044 |
6b54739846a781dd5d3ac3228c12438b |
2020-10-05T14:21:28.411Z |
5f7b2be831a8c6681cfb9850 |
0 |
| 4975 |
DR-546-MA |
546 |
MA |
DR |
1978-02-10T05:00:00.000Z |
1978 |
Flood |
COASTAL STORMS, FLOOD, ICE & SNOW |
0 |
1 |
... |
7 |
7 |
25007 |
99007 |
Dukes (County) |
78044 |
7d9e79eacde69ff26f56c6abfc41bcbe |
2020-10-05T14:21:28.412Z |
5f7b2be831a8c6681cfb9852 |
0 |
| 4976 |
DR-546-MA |
546 |
MA |
DR |
1978-02-10T05:00:00.000Z |
1978 |
Flood |
COASTAL STORMS, FLOOD, ICE & SNOW |
0 |
1 |
... |
5 |
5 |
25005 |
99005 |
Bristol (County)(in (P)MSA 1120,1200,2480,5400... |
78044 |
44a18d427378b578ca5082f23649f90c |
2020-10-05T14:21:28.411Z |
5f7b2be831a8c6681cfb9857 |
0 |
| 4977 |
DR-546-MA |
546 |
MA |
DR |
1978-02-10T05:00:00.000Z |
1978 |
Flood |
COASTAL STORMS, FLOOD, ICE & SNOW |
0 |
1 |
... |
9 |
9 |
25009 |
99009 |
Essex (County)(in PMSA 1120,4160,7090) |
78044 |
69e5446f5f1aa650c9dd62b132584a9d |
2020-10-05T14:21:28.414Z |
5f7b2be831a8c6681cfb985f |
0 |
| 4979 |
DR-546-MA |
546 |
MA |
DR |
1978-02-10T05:00:00.000Z |
1978 |
Flood |
COASTAL STORMS, FLOOD, ICE & SNOW |
0 |
1 |
... |
19 |
19 |
25019 |
99019 |
Nantucket (County) |
78044 |
d63a74daea9f57409505b4aa19b3a090 |
2020-10-05T14:21:28.416Z |
5f7b2be831a8c6681cfb986b |
0 |
5 rows × 27 columns
femaDeclarationString object
disasterNumber int64
state object
declarationType object
declarationDate object
fyDeclared int64
incidentType object
declarationTitle object
ihProgramDeclared int64
iaProgramDeclared int64
paProgramDeclared int64
hmProgramDeclared int64
incidentBeginDate object
incidentEndDate object
disasterCloseoutDate object
fipsStateCode int64
helperState int64
fipsCountyCode int64
helperCounty int64
fipscode int64
placeCode int64
designatedArea object
declarationRequestNumber int64
hash object
lastRefresh object
id object
fire int64
dtype: object
#truncate start date from timestamp to only include yyyy-mm-dd
disaster_df['start_date'] = disaster_df['incidentBeginDate'].apply(lambda x:x[:10])
#disaster_df['end_date'] = disaster_df['incidentEndDate'].apply(lambda x:x[:10]) #the data is not clean
sum(disaster_df['incidentBeginDate'] == disaster_df['incidentEndDate'])
#incidentBeginData is not always same with incidentEndDate, so we need to generate one row for each date from begin to end date
8398
disaster_df['incidentEndDate'].head()
0 1953-05-02T04:00:00.000Z
1 1953-05-15T04:00:00.000Z
2 1953-06-06T04:00:00.000Z
3 1953-06-11T04:00:00.000Z
4 1953-06-11T04:00:00.000Z
Name: incidentEndDate, dtype: object
#clean up end date from timestamp to only include yyyy-mm-dd
end_date = []
for i in disaster_df.iterrows():
try:
end_date.append(i[1]['incidentEndDate'][:10])
except:
end_date.append(i[1]['start_date'])
disaster_df['end_date'] = end_date
|
femaDeclarationString |
disasterNumber |
state |
declarationType |
declarationDate |
fyDeclared |
incidentType |
declarationTitle |
ihProgramDeclared |
iaProgramDeclared |
... |
fipscode |
placeCode |
designatedArea |
declarationRequestNumber |
hash |
lastRefresh |
id |
fire |
start_date |
end_date |
| 0 |
DR-1-GA |
1 |
GA |
DR |
1953-05-02T04:00:00.000Z |
1953 |
Tornado |
TORNADO |
0 |
1 |
... |
13000 |
0 |
Statewide |
53013 |
2f28952448e0a666d367ca3f854c81ec |
2020-10-05T14:21:20.694Z |
5f7b2be031a8c6681cfb4342 |
0 |
1953-05-02 |
1953-05-02 |
| 1 |
DR-2-TX |
2 |
TX |
DR |
1953-05-15T04:00:00.000Z |
1953 |
Tornado |
TORNADO & HEAVY RAINFALL |
0 |
1 |
... |
48000 |
0 |
Statewide |
53003 |
c5a1a4a1030d6730d9c562cdbe7c830f |
2020-10-05T14:21:20.696Z |
5f7b2be031a8c6681cfb4345 |
0 |
1953-05-15 |
1953-05-15 |
| 2 |
DR-5-MT |
5 |
MT |
DR |
1953-06-06T04:00:00.000Z |
1953 |
Flood |
FLOODS |
0 |
1 |
... |
30000 |
0 |
Statewide |
53006 |
59c5483387ca13c6a3c1bc692f4860e1 |
2020-10-05T14:21:20.698Z |
5f7b2be031a8c6681cfb4348 |
0 |
1953-06-06 |
1953-06-06 |
| 3 |
DR-7-MA |
7 |
MA |
DR |
1953-06-11T04:00:00.000Z |
1953 |
Tornado |
TORNADO |
0 |
1 |
... |
25000 |
0 |
Statewide |
53009 |
6bab17e16984fc75f61a8445df3e95d9 |
2020-10-05T14:21:20.699Z |
5f7b2be031a8c6681cfb434b |
0 |
1953-06-11 |
1953-06-11 |
| 4 |
DR-8-IA |
8 |
IA |
DR |
1953-06-11T04:00:00.000Z |
1953 |
Flood |
FLOOD |
0 |
1 |
... |
19000 |
0 |
Statewide |
53008 |
e258e9dd25fac73939f59c8ffb5308f5 |
2020-10-05T14:21:20.700Z |
5f7b2be031a8c6681cfb434e |
0 |
1953-06-11 |
1953-06-11 |
5 rows × 29 columns
sum(disaster_df['fire']), sum(disaster_df['incidentType'] == "Fire")
(3461, 3461)
60223
#how many unique fips code
zip_fips_df["FIPS code"].nunique()
3223
zip_fips_df["ZIP"].nunique()
39456
disaster_df["fipscode"].nunique()
3319
#get all the cols we need
cols = ['fipscode', 'start_date', 'end_date', 'fire']
fire = disaster_df[cols][disaster_df['fire'] == 1]
fire.head(3)
|
fipscode |
start_date |
end_date |
fire |
| 9 |
33000 |
1953-07-02 |
1953-07-02 |
1 |
| 63 |
6000 |
1956-12-29 |
1956-12-29 |
1 |
| 107 |
16000 |
1960-07-22 |
1960-07-22 |
1 |
fire[fire['start_date'] != fire['end_date']][:3]
|
fipscode |
start_date |
end_date |
fire |
| 6501 |
6053 |
1985-06-26 |
1985-07-19 |
1 |
| 6502 |
6079 |
1985-06-26 |
1985-07-19 |
1 |
| 6503 |
6085 |
1985-06-26 |
1985-07-19 |
1 |
3461
#save cleaned fire data with date and fipscode
import csv
with open('cleaned_data/cleaned_fire_data.csv', 'a') as outputfile:
writer = csv.writer(outputfile, delimiter=',')
header = ['fipscode', 'date', 'fire']
writer.writerow(header)
for i in fire.iterrows():
if i[1]['start_date'] == i[1]['end_date']:
val = [i[1]['fipscode'], i[1]['start_date'], i[1]['fire']]
writer.writerow(val)
else:
date_range = list(pd.date_range(start=i[1]['start_date'],end=i[1]['end_date']))
for d in date_range:
val = [i[1]['fipscode'], str(d)[:10], i[1]['fire']]
writer.writerow(val)
#exam the data
clean_fire_df = pd.read_csv("cleaned_fire_data.csv")
clean_fire_df.columns = ['fipscode', 'date', 'fire']
clean_fire_df.head()
|
fipscode |
date |
fire |
| 0 |
6000 |
1956-12-29 |
1 |
| 1 |
16000 |
1960-07-22 |
1 |
| 2 |
6000 |
1961-11-16 |
1 |
| 3 |
16009 |
1967-08-30 |
1 |
| 4 |
16017 |
1967-08-30 |
1 |
fipscode int64
date object
fire int64
dtype: object
3) Join weather data and fire data
complete_df = weather_fips_df.merge(clean_fire_df, how = 'left', left_on = ['FIPS code', 'date'], right_on=['fipscode', 'date'])
# explore the joined data
len(complete_df) #the same zip code may
16385692
complete_df[~complete_df['fipscode'].isnull()][:5]
|
date |
zipcode |
zip |
PRCP |
SNOW |
SNWD |
TMAX |
TMIN |
TOBS |
ZIP |
COUNTYNAME |
STATE |
FIPS code |
fipscode |
fire |
| 118197 |
1999-12-03 |
1420 |
01420 |
0.0 |
0.0 |
0.0 |
100.0 |
11.0 |
94.0 |
1420 |
Worcester County |
MA |
25027 |
25027.0 |
1.0 |
| 118198 |
1999-12-04 |
1420 |
01420 |
10.0 |
0.0 |
0.0 |
111.0 |
28.0 |
94.0 |
1420 |
Worcester County |
MA |
25027 |
25027.0 |
1.0 |
| 118199 |
1999-12-05 |
1420 |
01420 |
0.0 |
0.0 |
0.0 |
156.0 |
-11.0 |
94.0 |
1420 |
Worcester County |
MA |
25027 |
25027.0 |
1.0 |
| 118200 |
1999-12-06 |
1420 |
01420 |
107.0 |
0.0 |
0.0 |
128.0 |
67.0 |
94.0 |
1420 |
Worcester County |
MA |
25027 |
25027.0 |
1.0 |
| 118201 |
1999-12-07 |
1420 |
01420 |
122.0 |
0.0 |
0.0 |
111.0 |
28.0 |
94.0 |
1420 |
Worcester County |
MA |
25027 |
25027.0 |
1.0 |
#fill in all no-matching label with zero
complete_df['fire'] = complete_df['fire'].fillna(0)
# the percentage of positive data is around 0.3%. The data is super unbalanced
len(complete_df[complete_df['fire'] == 1])/len(complete_df)
0.002887641242127583
Index(['date', 'zipcode', 'zip', 'PRCP', 'SNOW', 'SNWD', 'TMAX', 'TMIN',
'TOBS', 'ZIP', 'COUNTYNAME', 'STATE', 'FIPS code', 'fipscode', 'fire'],
dtype='object')
#save clean data ready for model training
keep_cols = ['date', 'zip', 'FIPS code', 'PRCP', 'SNOW', 'SNWD', 'TMAX', 'TMIN', 'TOBS', 'fire']
complete_df[keep_cols].to_csv("cleaned_data/model_data_all.csv", index=False)
Train model
1) train test split
# load ready-for-model data
df = pd.read_csv("cleaned_data/model_data_all.csv")
|
date |
zip |
FIPS code |
PRCP |
SNOW |
SNWD |
TMAX |
TMIN |
TOBS |
fire |
| 0 |
1950-01-01 |
601 |
72001 |
18.0 |
0.0 |
0.0 |
183.0 |
128.0 |
156.0 |
0.0 |
| 1 |
1950-01-01 |
601 |
72113 |
18.0 |
0.0 |
0.0 |
183.0 |
128.0 |
156.0 |
0.0 |
| 2 |
1950-01-02 |
601 |
72001 |
18.0 |
0.0 |
0.0 |
194.0 |
122.0 |
167.0 |
0.0 |
16385692
X = df[['PRCP', 'SNOW', 'SNWD', 'TMAX', 'TMIN', 'TOBS']]
y = df['fire']
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.1, random_state=42)
2) scale and downsample
# scale training data
scaler = preprocessing.StandardScaler().fit(X_train)
scaled_X_train = scaler.transform(X_train)
#downsample the zero labels by 99%
mask = y_train.apply(lambda c: c>0 or random.random() > 0.99)
X_train_bal = scaled_X_train[mask]
y_train_bal = y_train[mask]
len(X_train), len(X_train_bal), len(y_train[y_train == 1]), len(y_train_bal[y_train_bal ==1]), len(y_train[y_train == 0]), len(y_train_bal[y_train_bal ==0])
(14747122, 189151, 42655, 42655, 14704467, 146496)
#the ratio of positive vs. negative after downsample
len(y_train_bal[y_train_bal ==1])/len(y_train_bal[y_train_bal ==0])
0.2911683595456531
# scale test data
scaled_X_test = scaler.transform(X_test)
3) MLP classifier
clf_bal = MLPClassifier(solver='lbfgs', alpha=1e-5, hidden_layer_sizes=(5, 2), random_state=1)
clf_bal.fit(X_train_bal, y_train_bal)
/Users/mo-b/anaconda3/lib/python3.7/site-packages/sklearn/neural_network/_multilayer_perceptron.py:470: ConvergenceWarning: lbfgs failed to converge (status=1):
STOP: TOTAL NO. of ITERATIONS REACHED LIMIT.
Increase the number of iterations (max_iter) or scale the data as shown in:
https://scikit-learn.org/stable/modules/preprocessing.html
self.n_iter_ = _check_optimize_result("lbfgs", opt_res, self.max_iter)
MLPClassifier(activation='relu', alpha=1e-05, batch_size='auto', beta_1=0.9,
beta_2=0.999, early_stopping=False, epsilon=1e-08,
hidden_layer_sizes=(5, 2), learning_rate='constant',
learning_rate_init=0.001, max_fun=15000, max_iter=200,
momentum=0.9, n_iter_no_change=10, nesterovs_momentum=True,
power_t=0.5, random_state=1, shuffle=True, solver='lbfgs',
tol=0.0001, validation_fraction=0.1, verbose=False,
warm_start=False)
# accuracy
clf_bal.score(scaled_X_test, y_test)
0.9735952690455703
array([0., 1.])
# auc score
prob_pred = clf_bal.predict_proba(scaled_X_test)[:, 1] # only get the predicted probability for class 1
auc_score = roc_auc_score(y_test, prob_pred)
auc_score
0.7337490009777365
y_pred = clf_bal.predict(scaled_X_test)
confusion_matrix(y_test, y_pred)
# tn, fp
# fn, tp
array([[1594599, 39310],
[ 3956, 705]])
#plot roc curve
# metrics.plot_roc_curve(clf_bal, scaled_X_test, y_test)
# plt.title("Fire prediction - ROC curve for MLP Classifier")
# plt.show()
# fine tune model
parameters = []
auc_scores = []
hidden_layer_sizes = [(5,2), (5,5), (10,5)] #size of each hidden layer
solvers = ['adam','sgd', 'lbfgs']
alphas = [0.001, 0.0001, 0.00001] #regularization term
for hidden_layer_size in hidden_layer_sizes:
for solver in solvers:
for alpha in alphas:
mlp = MLPClassifier(alpha=alpha, hidden_layer_sizes=hidden_layer_size, random_state=1, solver=solver)
mlp.fit(X_train_bal, y_train_bal)
prob_pred = mlp.predict_proba(scaled_X_test)[:, 1]
auc_score = roc_auc_score(y_test, prob_pred)
parameters.append({"hidden_layer_size":hidden_layer_size, "solver":solver, "alpha":alpha})
auc_scores.append(auc_score)
#get the parameters for best data
max_idx = np.argmax(auc_scores)
auc_scores[max_idx], parameters[max_idx]
(0.7594437575487328,
{'hidden_layer_size': (10, 5), 'solver': 'adam', 'alpha': 1e-05})
#train model with best parameters
best_mlp = MLPClassifier(alpha=1e-05, hidden_layer_sizes=(10, 5), random_state=1, solver='adam')
best_mlp.fit(X_train_bal, y_train_bal)
MLPClassifier(activation='relu', alpha=1e-05, batch_size='auto', beta_1=0.9,
beta_2=0.999, early_stopping=False, epsilon=1e-08,
hidden_layer_sizes=(10, 5), learning_rate='constant',
learning_rate_init=0.001, max_fun=15000, max_iter=200,
momentum=0.9, n_iter_no_change=10, nesterovs_momentum=True,
power_t=0.5, random_state=1, shuffle=True, solver='adam',
tol=0.0001, validation_fraction=0.1, verbose=False,
warm_start=False)
#roc for best mlp classifier for testing data
metrics.plot_roc_curve(best_mlp, scaled_X_test, y_test)
plt.title("Fire prediction - ROC curve for MLP Classifier")
plt.show()

#roc for best mlp classifier for training data
metrics.plot_roc_curve(best_mlp, scaled_X_train, y_train)
plt.title("Fire prediction - ROC curve for MLP Classifier with training data")
plt.show()

4) random forest classifier
rf = RandomForestClassifier(max_depth=10, random_state=0)
rf.fit(X_train_bal, y_train_bal)
RandomForestClassifier(bootstrap=True, ccp_alpha=0.0, class_weight=None,
criterion='gini', max_depth=10, max_features='auto',
max_leaf_nodes=None, max_samples=None,
min_impurity_decrease=0.0, min_impurity_split=None,
min_samples_leaf=1, min_samples_split=2,
min_weight_fraction_leaf=0.0, n_estimators=100,
n_jobs=None, oob_score=False, random_state=0, verbose=0,
warm_start=False)
# auc score
prob_pred = rf.predict_proba(scaled_X_test)[:, 1] # only get the predicted probability for class 1
auc_score = roc_auc_score(y_test, prob_pred)
auc_score
0.797966470622066
# fine tune model
rf_parameters = []
rf_auc_scores = []
n_estimators = [10, 50, 100]
criterions = ['gini','entropy']
max_depths = [10, 50, 100]
for criterion in criterions:
for n_estimator in n_estimators:
for max_depth in max_depths:
rfm = RandomForestClassifier(max_depth=max_depth,n_estimators =n_estimator,criterion=criterion, random_state=1)
rfm.fit(X_train_bal, y_train_bal)
prob_pred = rfm.predict_proba(scaled_X_test)[:, 1]
auc_score = roc_auc_score(y_test, prob_pred)
rf_parameters.append({"n_estimator":n_estimator, "criterion":criterion, "max_depth":max_depth})
rf_auc_scores.append(auc_score)
#get best parameters for random forest classifier
max_idx = np.argmax(rf_auc_scores)
rf_auc_scores[max_idx], rf_parameters[max_idx]
(0.8416267396854684,
{'n_estimator': 100, 'criterion': 'entropy', 'max_depth': 50})
#train model with best parameters
best_rf = RandomForestClassifier(n_estimators=100, criterion='entropy', max_depth=50 )
best_rf.fit(X_train_bal, y_train_bal)
RandomForestClassifier(bootstrap=True, ccp_alpha=0.0, class_weight=None,
criterion='entropy', max_depth=50, max_features='auto',
max_leaf_nodes=None, max_samples=None,
min_impurity_decrease=0.0, min_impurity_split=None,
min_samples_leaf=1, min_samples_split=2,
min_weight_fraction_leaf=0.0, n_estimators=100,
n_jobs=None, oob_score=False, random_state=None,
verbose=0, warm_start=False)
best_rf.score(scaled_X_test, y_test)
0.9057342682949157
best_rf.score(scaled_X_train, y_train)
0.9066968456624961
#plot roc curve
metrics.plot_roc_curve(best_rf, scaled_X_test, y_test)
plt.title("Fire prediction - ROC curve for random forest Classifier")
plt.show()

#plot roc curve
metrics.plot_roc_curve(best_rf, scaled_X_train, y_train)
plt.title("Fire prediction - ROC curve for random forest Classifier with training data")
plt.show()

- Based on the auc scores, random forest model (0.84) is better than MLPClassifier (0.76). We will use the fine tuned random forest model to predict the probability of fire event with forecast NOAA weather data.
best_rf.feature_importances_
array([0.08900428, 0.0059088 , 0.02556477, 0.30069328, 0.278647 ,
0.30018187])
Predict future fire
1) load predicted weather data
pred_weather_df = pd.read_csv("cleaned_data/NOAA_weather_forecast_predictions.csv")
|
zipcode |
year |
PRCP |
SNOW |
SNWD |
TMAX |
TMIN |
TOBS |
| 0 |
16601 |
2030 |
36.704178 |
6.832971 |
5.034125 |
155.709286 |
57.087498 |
79.935546 |
| 1 |
16601 |
2040 |
38.987804 |
8.066879 |
-0.581523 |
157.545249 |
60.140693 |
78.845724 |
| 2 |
16601 |
2050 |
41.276487 |
9.303487 |
-6.195984 |
159.381684 |
63.195606 |
77.752849 |
| 3 |
16601 |
2060 |
43.571408 |
10.541236 |
-11.812570 |
161.216156 |
66.252145 |
76.652903 |
| 4 |
16601 |
2070 |
45.849895 |
11.775522 |
-17.431140 |
163.057915 |
69.306966 |
75.563086 |
2) scale predicted weather data
weather_forecast = pred_weather_df[['PRCP', 'SNOW', 'SNWD', 'TMAX', 'TMIN', 'TOBS']]
scaled_weather_forecast = scaler.transform(weather_forecast)
3) predict fire
fire_prob_pred = best_rf.predict_proba(scaled_weather_forecast)[:, 1]
pred_weather_df['Fire'] = fire_prob_pred
|
zipcode |
year |
PRCP |
SNOW |
SNWD |
TMAX |
TMIN |
TOBS |
Fire |
| 0 |
16601 |
2030 |
36.704178 |
6.832971 |
5.034125 |
155.709286 |
57.087498 |
79.935546 |
0.22 |
| 1 |
16601 |
2040 |
38.987804 |
8.066879 |
-0.581523 |
157.545249 |
60.140693 |
78.845724 |
0.00 |
| 2 |
16601 |
2050 |
41.276487 |
9.303487 |
-6.195984 |
159.381684 |
63.195606 |
77.752849 |
0.01 |
| 3 |
16601 |
2060 |
43.571408 |
10.541236 |
-11.812570 |
161.216156 |
66.252145 |
76.652903 |
0.00 |
| 4 |
16601 |
2070 |
45.849895 |
11.775522 |
-17.431140 |
163.057915 |
69.306966 |
75.563086 |
0.05 |
#save fire prediction to csv file
pred_weather_df.to_csv('cleaned_data/fire_prediction_w_noaa_weather_forecast.csv', index=False)
3260
check = pd.read_csv('cleaned_data/fire_prediction_w_noaa_weather_forecast.csv')
|
zipcode |
year |
PRCP |
SNOW |
SNWD |
TMAX |
TMIN |
TOBS |
Fire |
| 0 |
16601 |
2030 |
36.704178 |
6.832971 |
5.034125 |
155.709286 |
57.087498 |
79.935546 |
0.22 |
| 1 |
16601 |
2040 |
38.987804 |
8.066879 |
-0.581523 |
157.545249 |
60.140693 |
78.845724 |
0.00 |
| 2 |
16601 |
2050 |
41.276487 |
9.303487 |
-6.195984 |
159.381684 |
63.195606 |
77.752849 |
0.01 |
| 3 |
16601 |
2060 |
43.571408 |
10.541236 |
-11.812570 |
161.216156 |
66.252145 |
76.652903 |
0.00 |
| 4 |
16601 |
2070 |
45.849895 |
11.775522 |
-17.431140 |
163.057915 |
69.306966 |
75.563086 |
0.05 |